cs189-note01
第一节Lecture主要讲了如何选择好的Classifier,以及关于作业与训练的问题。
Classification
-
nearest neighbor classifier:decision boundary is not computed,but it classifies all the training data correctly。It’s overfitting!.the boundary is too intricate to reflect reality!
-
linear classifier:the decision boundary is explicitly computed by the classifier,and boundary is more smoother!.
Images are points in 16-dimensional space. Linear decision boundary is a hyperplane.
Train,Validate,Test
How we classify:
- We are given labeled data—sample points with class labels. – Hold back a subset of the labeled points, called the validation set. Maybe 20%. The other 80% is the training set. Warning: the term training data is not used consistently. Often “training data” refers to all the labeled data. You have to judge from context.
- – Train one or more classifiers: they learn to distinguish 7 from not 7. Use training set to learn model weights. Do NOT use validation set to train!!!
- – Usually, train multiple learning algorithms, or one algorithm with multiple hyperparameter settings, or both using the same training set for each.
- – Validate the trained classifiers on the validation set. Choose classifier/hyperparameters with lowest validation error. Called validation. When we do validation, we are not learning any more. We are checking what classes our trained classifiers assign to our validation set, and counting how often they’re right. We use this to judge our models—not how well they remember the training set labels.
- – Optional: Test the best classifer on a test set of NEW data. Final evaluation. Typically you do NOT have the labels. But somebody else might have them, and assign you a score!
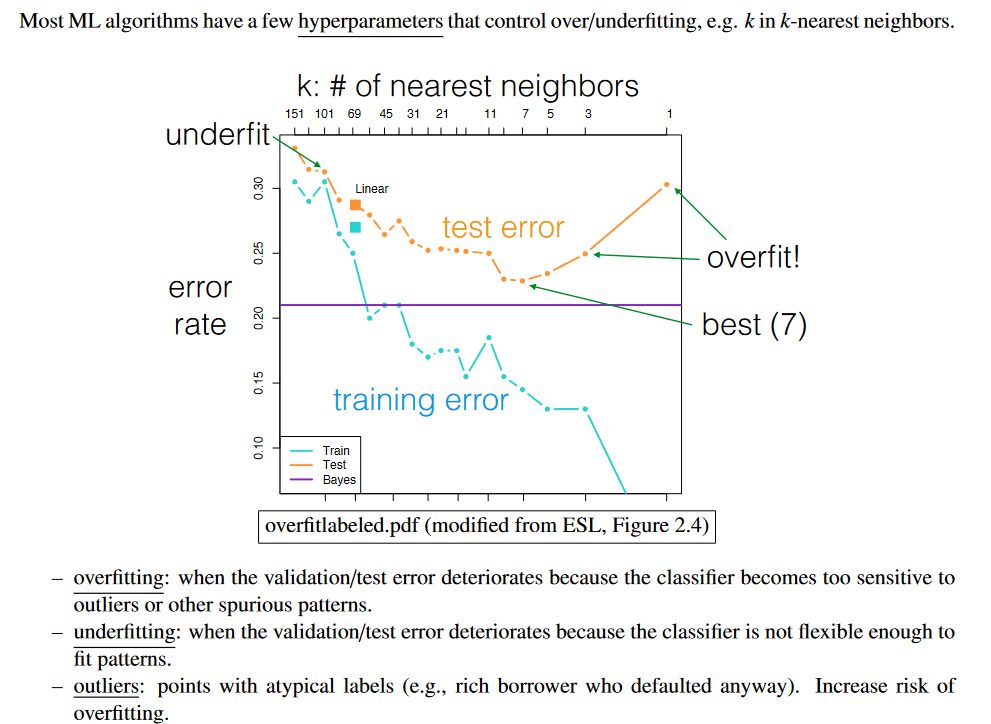
3 kinds of error:
- Training error: fraction of training set not classified correctly. This is zero with the 1-nearest neighbor classifier, but nonzero with the 15-nearest neighbor and linear classifiers. But that doesn’t mean the 1-nearest neighbor classifier is always better. Remember that you cannot include the validation data in this calculation, even if somebody calls it “training data.”
- – Validation error: fraction of validation set misclassified. Use this to choose classifier/hyperparameters. You didn’t use the validation set to train, so even the 1-nearest neighbor classifier can classify these points wrong. Validation error is almost always higher than training error.
- – Test error: fraction of test set misclassified. Used to evaluate you.
本文由作者按照
CC BY 4.0
进行授权