cs188-note15
Reinforcement Learning
In online planning, an agent must try exploration, during which it performs actions and receives feedback in the form of the successor states it arrives in and the corresponding rewards it reaps. The agent uses this feedback to estimate an optimal policy through a process known as reinforcement learning before using this estimated policy for exploitation or reward maximization.
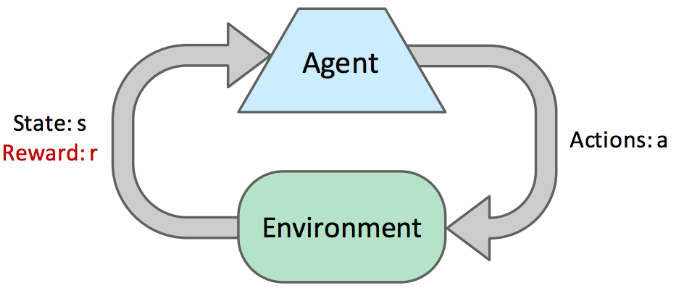
At each time step during online planning, an agent starts in a state s, then takes an action a and ends up in a successor state s′, attaining some reward r. Each (s, a, s′, r) tuple is known as a sample.
Often, an agent continues to take actions and collect samples in succession until arriving at a terminal state. Such a collection of samples is known as an episode.
There are two types of reinforcement learning, model-based learning and model-free learning.
- attempts to estimate the transition and reward functions with the samples attained during exploration before using these estimates to solve the MDP normally with value or policy iteration
- attempts to estimate the values or Q-values of states directly, without ever using any memory to construct a model of the rewards and transitions in the MDP.
Model-Based Learning
